小电影的网站PYTHON爬虫(如何使用 Python 爬虫抓取小电影的网站资源)
在当今数字化的时代,互联网上的信息资源可谓是海量。其中,小电影的网站作为一类特殊的存在,吸引了众多用户的关注。对于那些对小电影内容感兴趣的人来说,了解如何使用 Python 爬虫抓取这些网站的资源是一项有价值的技能。将深入探讨小电影的网站 PYTHON 爬虫的相关内容,为读者提供背景信息,并从多个方面详细阐述如何进行抓取。
什么是小电影的网站 PYTHON 爬虫?
小电影的网站 PYTHON 爬虫是一种程序,它能够自动访问和抓取小电影的网站上的资源。通过编写爬虫代码,我们可以模拟浏览器的行为,从网站中提取出视频、图片、文本等各种信息。
为什么要抓取小电影的网站资源?
抓取小电影的网站资源可能有多种原因。以下是一些常见的动机:
1. 个人学习和研究:对电影制作、视频编辑或相关领域感兴趣的人可以通过抓取资源来学习和研究不同的技术和风格。
2. 内容获取:有时候,我们可能希望获取特定小电影的资源,以便在其他平台上观看或分享。
3. 数据收集:对于市场研究或数据分析的目的,抓取小电影网站上的信息可以提供有关用户行为、趋势等方面的数据。
准备工作
在开始抓取小电影的网站资源之前,我们需要进行一些准备工作:
1. 选择合适的爬虫框架:有许多 Python 爬虫框架可供选择,如 Scrapy、BeautifulSoup 等。根据自己的需求和经验选择适合的框架。
2. 了解网站的结构和规则:仔细观察小电影网站的结构,了解页面的布局和请求方式,以便正确地抓取所需的资源。
3. 遵守法律法规:确保你的抓取行为符合法律法规,尊重网站的版权和使用条款。
抓取过程
抓取小电影的网站资源的过程可以分为以下几个步骤:
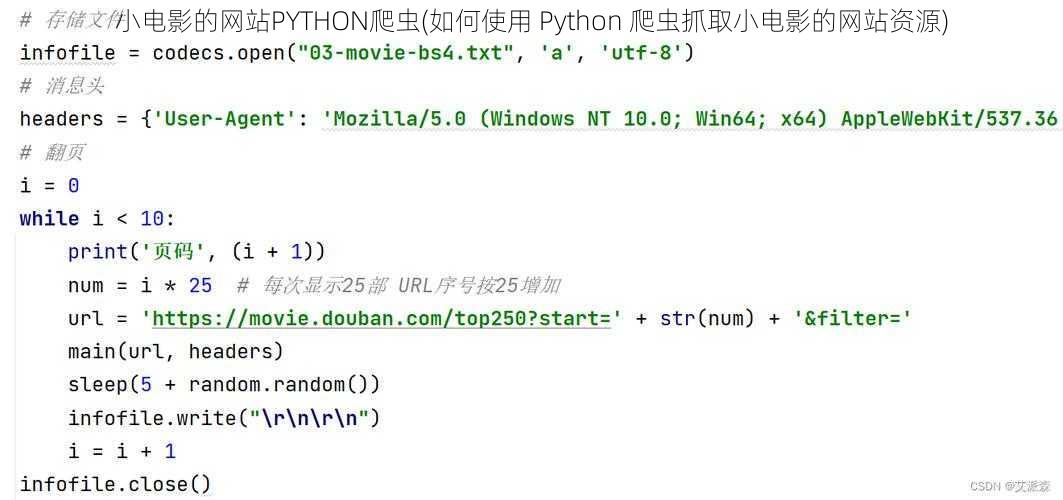
1. 发起请求:使用爬虫框架发送 HTTP 请求到小电影网站的页面。
2. 解析响应:解析服务器返回的响应数据,通常使用 BeautifulSoup 或其他解析库来提取所需的信息。
3. 提取资源:根据解析出的信息,找到视频、图片等资源的链接,并将其提取出来。
4. 存储资源:将提取到的资源保存到本地或其他存储介质中,例如文件或数据库。
注意事项
在抓取小电影的网站资源时,需要注意以下几点:
1. 反爬虫机制:许多网站都设置了反爬虫机制,可能会检测到爬虫的行为并采取限制措施。要了解并遵守网站的规则,避免触发这些机制。
2. 道德和法律问题:抓取小电影资源可能涉及到道德和法律问题,确保你的行为合法合规,并尊重他人的权益。
3. 隐私和安全:不要抓取用户的个人信息或其他敏感数据,确保爬虫的操作不会侵犯他人的隐私。
4. 网站信誉:选择合法、信誉良好的小电影网站进行抓取,避免参与非法或有害的活动。
介绍了小电影的网站 PYTHON 爬虫的基本概念和原理,并提供了抓取资源的一般步骤和注意事项。通过使用 Python 爬虫,我们可以获取小电影网站上的丰富资源,但要在合法、合规的前提下进行,并尊重网站的规则和用户的权益。
需要注意的是,抓取小电影资源可能涉及到法律和道德问题,因此在进行任何抓取操作之前,请确保你已经了解并遵守相关的法律法规。也要尊重网站的版权和使用条款,不要将抓取到的资源用于非法或不道德的目的。
对于那些对小电影内容感兴趣的人,建议通过合法的渠道获取资源,例如购买正版影片或使用合法的在线视频平台。这样不仅可以支持内容创作者,还能确保你获得高质量的观影体验。
未来,随着技术的不断发展和法律法规的不断完善,小电影的网站爬虫领域可能会面临新的挑战和机遇。对这一领域感兴趣的人可以继续关注相关的发展动态,并不断探索和创新,以开发出更加高效和合法的爬虫工具。